Cache using Caffeine in spring boot webflux
In this article I am sharing my experience with caffeine caching in spring boot webflux application. Let’s begin with a basic understanding of what is caching ?
What is Caching?
Caching is the process of storing data in the cache. A cache is a high-speed data storage layer which stores a subset of data, typically transient in nature, so that future requests for that data are served up faster than is possible by accessing the data’s primary storage location.
Great !! Now we have a basic understanding of what caching is. Let’s see caching patterns
- Cache-Aside
Load data on demand into a cache from a data store. This can improve performance and also helps to maintain consistency between data held in the cache and data in the underlying data store.

2. Read-Through
When the cache is asked for the value associated with a given key and such an entry does not exist within the cache, the cache retrieves the data from the db, then caches the value, then returns it to the caller.
3. Write-Through
In this write strategy, data is first written to the cache and then to the database. The cache sits in-line with the database and writes always go through the cache to the main database. This helps cache maintain consistency with the main database.
4. Write-Back/Behind
Here, the application writes data to the cache which stores the data and acknowledges the data that is read makes its way into the cache.
Now let’s dive into the main agenda of this article. That is we’re going to learn how to use the Caching Abstraction using caffeine in Spring boot Webflux, and generally improve the performance of our system.
For reactive streams, you can’t reliably use a LoadingCache because it’s blocking by default. Thankfully, tapping into a couple of basic features of reactive streams and caffeine can get us there.
Caffeine is a high-performance Java 8 based caching library providing a near-optimal hit rate. It provides an in-memory cache very similar to the Google Guava API. Spring Boot Cache starters are auto-configured CaffeineCacheManager if it finds the Caffeine in the classpath. The Spring Framework provides support for transparently adding caching to an application.
Let’s Dive in….
Let’s consider the need to display a list of books to the user. For this our API has to make different calls to upstream services to collate all data. It takes around 500 to 600 MS per request, but SLA is below 80 MS at 99 percentile. How are we going to achieve this ????
In this scenario caching is much more handy.
Let’s create custom annotation to enable caching. To do that we need to create an interface with Target as method and retention as runtime policy.

Now we can create AOP, before that let us create a bean which serves configured caffeine object. There you can set maximum size and expiry time.. etc
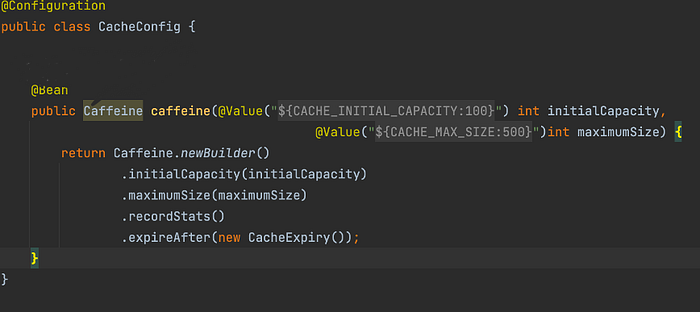
Let’s create AOP class to enable custom caching functionality using caffeine.
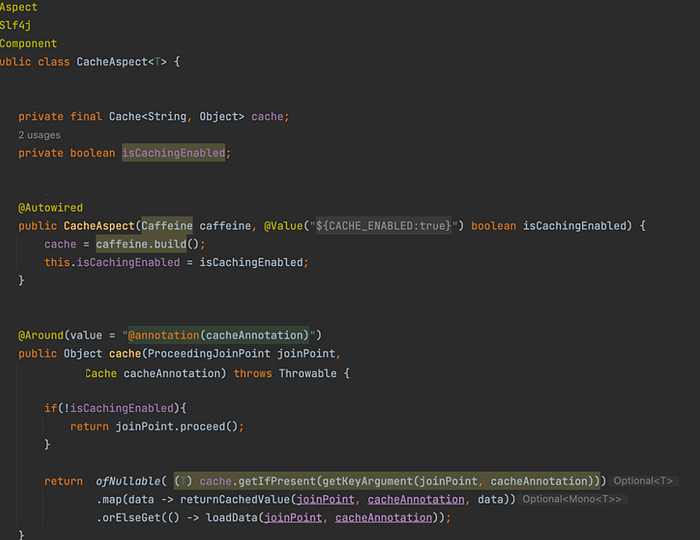

Now we are almost there. let’s add this annotation to book service method.

Voila.. that is it. Now you can see the magic where book service takes 0 milliseconds.

Summary :
In this post, we have discussed all about Caching, patterns of Cache, Caching annotations, Caffeine Caching and its configuration and how to add caching in Spring Boot webflux application with example.
Now you have learned how to implement caching in Spring Boot applications. With the help of caching we can increase the performance of applications and reduce the application host.
Thanks for reading.
If you like reading this article then please hold the clap button!
